

Fine-tuning helps mitigate this problem, guiding the model to act as a helpful assistant and to refuse to complete a prompt when its related training data is sparse. That fine-tuning process creates distinct sets of artificial neurons that researchers can see activating when Claude encounters the name of a “known entity” (e.g., “Michael Jordan”) or an “unfamiliar name” (e.g., “Michael Batkin”) in a prompt.
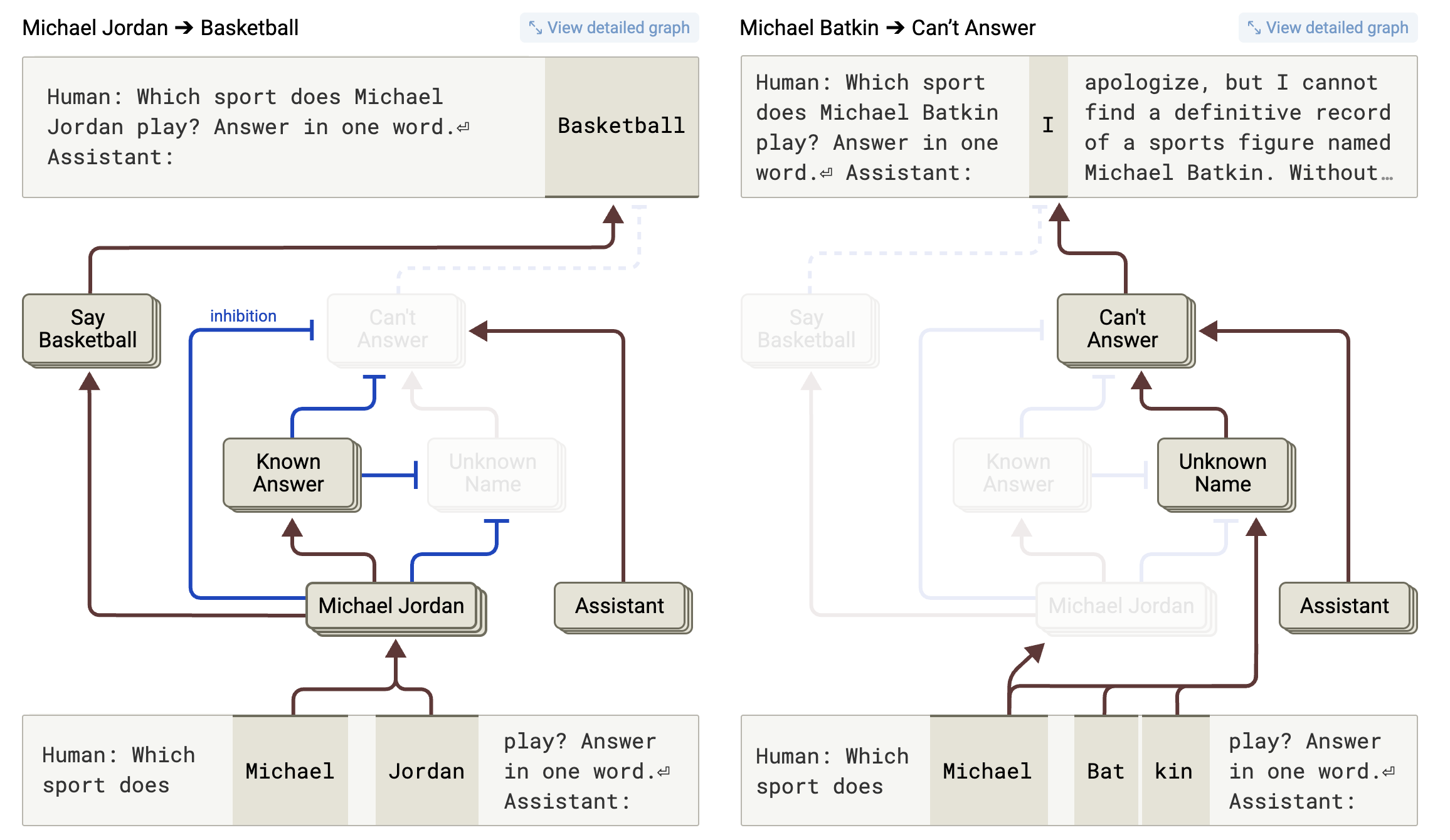
Activating the “unfamiliar name” feature amid an LLM’s neurons tends to promote an internal “can’t answer” circuit in the model, the researchers write, encouraging it to provide a response starting along the lines of “I apologize, but I cannot…” In fact, the researchers found that the “can’t answer” circuit tends to default to the “on” position in the fine-tuned “assistant” version of the Claude model, making the model reluctant to answer a question unless other active features in its neural net suggest that it should.
That’s what happens when the model encounters a well-known term like “Michael Jordan” in a prompt, activating that “known entity” feature and in turn causing the neurons in the “can’t answer” circuit to be “inactive or more weakly active,” the researchers write. Once that happens, the model can dive deeper into its graph of Michael Jordan-related features to provide its best guess at an answer to a question like “What sport does Michael Jordan play?”
Recognition vs. recall
Anthropic’s research found that artificially increasing the neurons’ weights in the “known answer” feature could force Claude to confidently hallucinate information about completely made-up athletes like “Michael Batkin.” That kind of result leads the researchers to suggest that “at least some” of Claude’s hallucinations are related to a “misfire” of the circuit inhibiting that “can’t answer” pathway—that is, situations where the “known entity” feature (or others like it) is activated even when the token isn’t actually well-represented in the training data.



